
Engenheiros de software enlouquecem pelas coisas mais ridículas. Nós gostamos de pensar que somos hiper-racionais, mas quando temos que escolher uma tecnologia, acabamos em uma espécie de frenesi – saltando do comentário Hacker News de uma pessoa para o blog de outro até que, em um estupor, flutuamos impotentes em direção à luz mais brilhante e inclinada na frente dela, ignorando o que estávamos procurando em primeiro lugar.
Não é assim que as pessoas racionais tomam decisões, mas é assim que os engenheiros de software decidem usar o MapReduce.
Como Joe Hellerstein estudou na sua classe de base de dados de graduação(54 min in):O negócio é que existem 5 empresas no mundo que executam trabalhos desse tamanho. Para todos os outros … você está fazendo todo esse I / O para tolerância a falhas que você realmente não precisava. As pessoas ficaram meio manias com o Google nos anos 2000: “faremos tudo da maneira que o Google faz, porque também administramos o maior serviço de dados da Internet do mundo” [inclina a cabeça para o lado e espera pelo riso]
Ter mais tolerância a falhas do que o necessário pode soar bem, mas leve em conta o custo: além de estar fazendo muito mais E / S, você pode estar migrando de um sistema maduro – com transações, índices e otimizadores de consulta – para algo relativamente surrado. Que grande passo para trás . Quantos usuários do Hadoop fazem essas concessões conscientemente? Quantos desses usuários fazem essas compensações com sabedoria?
O MapReduce / Hadoop é um alvo flexível neste ponto, porque até os coletores de carga perceberam que os aviões não estão a caminho. Mas a mesma observação pode ser feita de forma mais ampla: se você usa uma tecnologia originada em uma grande empresa, mas seu caso de uso é muito diferente, é improvável que você tenha chegado lá deliberadamente; Não, é mais provável que você tenha chegado lá através de uma crença ritualística de que imitar os gigantes traria as mesmas riquezas.

Ok, então sim: este é outro artigo “não se cultue”. Mas espere! Eu tenho uma lista de verificação útil para você, uma que você pode usar para tomar decisões melhores.
Cool Tech? UNPHAT
Da próxima vez que você se encontrar pesquisando alguma nova tecnologia interessante para (re) construir sua arquitetura, peço que pare e siga UNPHAT:
- Não comece a considerar soluções até entender o problema. Seu objetivo deve ser “resolver” o problema principalmente dentro do domínio do problema , não no domínio da solução.
- eNumerate várias soluções candidatas. Não comece a cutucar seu favorito!
- Considere uma solução candidata e leia o documento, se houver.
- Determinar o contexto histórico no qual a solução candidata foi projetada ou desenvolvida.
- Pesar Vantagens contra desvantagens. Determine o que foi de-priorizadopara alcançar o que foi priorizado.
- Pensar! Sobriamente e humildemente ponderar quão bem esta solução se adapta ao seu problema. Que fato precisaria ser diferente para você mudar de idéia? Por exemplo, quanto menores os dados precisam ser antes de você decidir não usar o Hadoop?
Você também não é Amazon
É bastante simples aplicar o UNPHAT. Considere minha conversa recente com uma empresa que considerou brevemente o uso do Cassandra para um fluxo de trabalho de leitura pesada sobre os dados que foram carregados em todas as noites:
Tendo lido o artigo da Dynamo e sabendo que Cassandra era uma derivada próxima, entendi que esses bancos de dados distribuídos priorizam a disponibilidade de gravação (a Amazon queria que a ação “adicionar ao carrinho” nunca falhasse). Eu também gostei que eles fizeram isso comprometendo a consistência, bem como basicamente todos os recursos presentes em um RDBMS tradicional. Mas a empresa com quem eu estava falando não precisava priorizar a disponibilidade de gravação, já que o padrão de acesso exigia uma grande gravação por dia. 🤔

Essa empresa considerou o Cassandra porque a consulta do PostgreSQL em questão estava demorando minutos, o que eles acharam ser uma limitação do hardware. Após algumas perguntas, determinamos que a tabela tinha cerca de 50 milhões de linhas e 80 bytes de largura, portanto, demoraria cerca de 5 segundos para ser lido na íntegra do SSD, se fosse necessário um FileScan completo. Isso é lento, mas são 2 ordens de magnitude mais rápidas que a consulta real. 🤔
Neste ponto, eu realmente queria fazer mais perguntas (entender o problema!) E comecei a pesar cerca de 5 estratégias para quando o problema crescesse (enumerar várias soluções candidatas!), Mas já estava bem claro que Cassandra teria sido a solução errada inteiramente. Tudo o que precisavam era algum ajuste de paciente, talvez remodelando alguns dos dados, talvez (mas provavelmente não) outra opção de tecnologia … mas certamente não o armazenamento de valor chave de alta disponibilidade de gravação que a Amazon criou para seu carrinho de compras!
Além disso, você não é LinkedIn
Fiquei surpreso ao descobrir que a empresa de um aluno havia escolhido arquitetar seu sistema em torno de Kafka. Isso foi surpreendente porque, até onde eu sabia, seus negócios processavam apenas algumas dúzias de transações de alto valor por dia – talvez algumas centenas em um bom dia. Nesse throughput, o armazenamento de dados primário pode ser uma gravação humana em um livro físico.
Em comparação, o Kafka foi projetado para lidar com o throughput de todos os eventos de análise no LinkedIn: um número monumental. Até alguns anos atrás, isso equivalia a cerca de 1 trilhão de eventos por dia, com picos de mais de 10 milhões de mensagens por segundo . Eu entendo que o Kafka ainda é útil para cargas de trabalho de taxa de transferência menores, mas 10 ordens de magnitude mais baixas?

Talvez os engenheiros realmente tenham tomado uma decisão informada com base em suas necessidades esperadas e uma boa compreensão da lógica de Kafka. Mas meu palpite é que eles se alimentaram do entusiasmo da comunidade (geralmente justificável) em torno de Kafka e pensaram pouco sobre se era o ajuste certo para o trabalho. Quero dizer … 10 ordens de magnitude!
Você não é Amazon, novamente
Mais popular do que o armazenamento de dados distribuído da Amazon é o padrão arquitetônico que eles atribuem a eles: dimensionamento: arquitetura orientada a serviços. Como Werner Vogels apontou nesta entrevista de 2006 por Jim Gray , a Amazon percebeu em 2001 que eles estavam lutando para escalar seu front end, e que uma arquitetura orientada a serviços acabou ajudando. Esse sentimento reverberou de um engenheiro para outro, até que startups com apenas alguns engenheiros e quase todos os usuários começaram a dividir seu aplicativo de brochura em nanoservices.
Mas quando a Amazon decidiu mudar para a SOA, eles tinham cerca de 7.800 funcionários e faturaram mais de US $ 3 bilhões .

Isso não quer dizer que você deva adiar SOA até chegar à marca de 7.800 funcionários … apenas pense por si mesmo . É a melhor solução para o seu problema? Qual é exatamente o seu problema e quais são outras maneiras de resolvê-lo?
Se você me disser que sua organização de engenharia de 50 pessoas iria parar sem a SOA, vou me perguntar por que tantas empresas maiores se dão bem com um aplicativo único grande, mas bem organizado.
Mesmo o Google não é o Google
O uso de mecanismos de fluxo de dados de grande escala como Hadoop e Spark pode ser particularmente engraçado: muitas vezes, um SGBD tradicional é mais adequado à carga de trabalho e, às vezes, o volume de dados é tão pequeno que pode caber na memória. Você sabia que pode comprar um terabyte de RAM por cerca de US $ 10.000? Mesmo se você tivesse um bilhão de usuários, isso daria a você 1kB de RAM por usuário para trabalhar.
Talvez isso não seja suficiente para sua carga de trabalho, e você precisará ler e gravar de volta no disco. Mas você precisa ler e escrever de volta para literalmente milhares de discos? Quantos dados você tem exatamente? GFS e MapReduce foram criados para lidar com o problema de computação em toda a web , como… recriar um índice de pesquisa em toda a web .
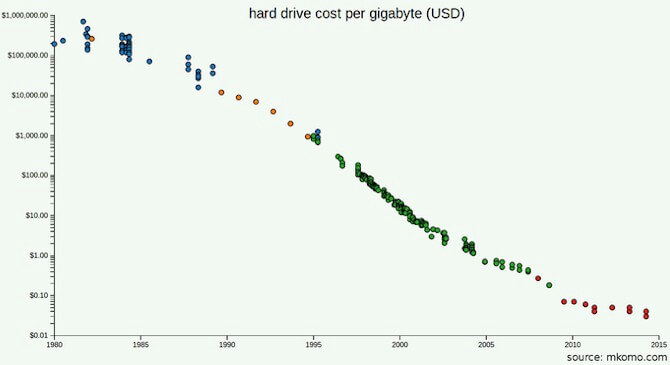
Talvez você tenha lido os documentos GFS e MapReduce e aprecie que parte do problema para o Google não era a capacidade, mas sim o throughput: eles distribuíam o armazenamento porque estava demorando demais para transmitir os bytes do disco. Mas qual é o rendimento dos dispositivos que você usará em 2017? Considerando que você não precisará de tantos deles quanto o Google, você pode comprar apenas os melhores? Quanto custaria usar SSDs?
Talvez você espere escalar. Mas você já fez a matemática? É provável que você acumule dados mais rapidamente do que a taxa na qual os preços das SSD irão diminuir? Quanto sua empresa precisaria crescer antes que todos os seus dados não cabessem mais em uma máquina? A partir de 2016, o Stack Exchange atendeu a 200 milhões de solicitações por dia, apoiadas por apenas quatro servidores SQL : um primário para o Stack Overflow, um primário para todo o restante e duas réplicas.
Novamente, você pode passar por um processo como o UNPHAT e ainda decidir usar o Hadoop ou o Spark. A decisão pode até ser a correta. O importante é que você realmente use a ferramenta certa para o trabalho . O Google sabe disso muito bem: assim que decidiram que o MapReduce não era a ferramenta certa para criar o índice, pararam de usá-lo.
Primeiro, entenda o problema
Minha mensagem não é nova, mas talvez seja a versão que fala com você, ou talvez a UNPHAT seja memorável o suficiente para você aplicá-la. Se não, você pode tentar a palestra de Rich Hickey, Hammock Driven Development , ou o livro Polya Como Resolvê-lo , ou o curso de Hamming, A Arte de Fazer Ciência e Engenharia . O que todos nós estamos implorando para você fazer é pensar ! E para realmente entender o problema que você está tentando resolver. Nas palavras galvânicas de Polya:É tolice responder a uma pergunta que você não entende. É triste trabalhar por um fim que você não deseja.